DDUMBFS a dumb de-duplicating filesystem for linux
This page has moved to http://www.magiksys.net/ddumbfs
 I
I
Overview
ddumfs is a filesystem for Linux released under GPL, doing de-duplication. De-duplication is a technique to avoid duplication of data on the same storage device do increase its capacity. ddumbfs try do to it without requiring to much resources from the system, using simple and reliable solutions.
A filesystem dedicated to hold backups only.
A backup share 99% of identical data with previous and next backups. Differential techniques exist to reduce the amount of data to save, but complicate backup handling and restore procedure. The idea of ddumbfs is to do the difference at filesystem level to allow any backup tools to take benefit of space saving without any constraints.
Moreover accesses to the backup data are less demanding than to the online one. Most backup tools generate big archive files in one continuous write. Read access to these file are infrequent and random read/write are really uncommon. Usually backup are done during the night and increase the backup time to increase retention period is valuable until the backup finishes before morning. Regarding these backup requirements, we can imaging increase disc capacity at cost of some flexibility shortage. The proof, is we have used and still use magnetic tapes for backup despite of its lack of flexibility !
Regarding these requirements, modern filesystems look overkill to just store backup archive ! This is where a dedicated filesystem like ddumbfs could bring more to backup applications !
The goal is to be able to backup data to low-cost Linux based NAS running ddumbfs.
 My personal final objective is to provide de-duplication to this crappy Maxtor NAS. If I can write to this NAS running a custom de-duplication enable Linux at 1 or 2Mo/s I would be very happy !
My personal final objective is to provide de-duplication to this crappy Maxtor NAS. If I can write to this NAS running a custom de-duplication enable Linux at 1 or 2Mo/s I would be very happy !
How does it works
When ddumbfs get a block of data for writing, if first calculate a hash for this block. Then it search in the index for this hash and return the stored address. If the hash is not found, the block is added to the storage and its address and hash are added to the index. A process called reclamation must handle file deletion and remove no more required blocks.
FUSE for linux, File system in user space
To start writing filesystem, I tried FUSE. In 4H I got my first prototype, version 0.1, written using FUSE for python API. Rewrite all these stuff in C took a lot more time. About 4 days to have a C-FUSE file system handling command line parameters, and the required python tools to format, debug, and access offline filesystem.
Last version is 0.3 with decent performances at the end
Version 0.1
My first idea was to use an existing filesystem to do indexing and storage. Every new block was stored in the ddfsblocks directory using its base64 encoded hash for name. The file where stored in ddfstop directory as a list of hash referencing the file blocks.
I get very good results when the amount of data was < 5Go for 4K blocks. The main problem is the numbers of file in the ddfsblocks directory. Store 10Go require 2.6 millions block and so many files ! EXT4 filesystem handle millions files quiet well but not well enough when its about to read or write only 4K. And above 10 millions files the system begin to crawl down ! Try to hash files into directories slow down the system a lot more, proof than EXT4 perform very well. Try to create 2 levels of directories for a total of 256.000 directories, then try to delete them to convince you !
| Operation on file of 1.2Go | Local HD ext4 | Local FUSE xmp | Local ddumbfs |
|---|---|---|---|
| copy from NFS (write) | 29.5Mo/s | 26.2Mo/s | 7.2Mo/s |
| md5sum (read) | 61.7Mo/s | 55.78Mo/s | 12.3Mo |
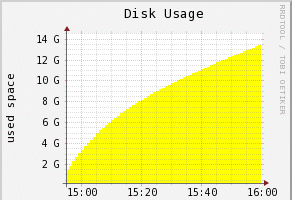 The disk usage shows the speed is decreasing with the number of blocks on the disk.
The disk usage shows the speed is decreasing with the number of blocks on the disk.
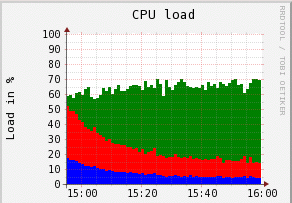 The CPU is highly loaded at the beginning, probably because of the SHA1 calculation. The decline because the cpu is waiting for disk io more and more.
The CPU is highly loaded at the beginning, probably because of the SHA1 calculation. The decline because the cpu is waiting for disk io more and more.
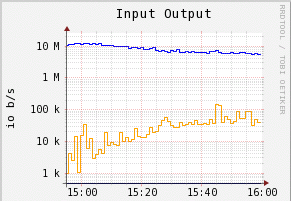 With the increase of block number, the system need more read access to search for a block with a matching hach.
With the increase of block number, the system need more read access to search for a block with a matching hach.
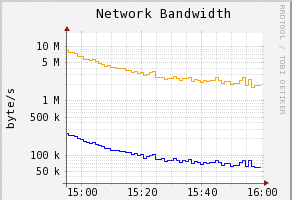 Inexorably the transfer speed is going down !
Inexorably the transfer speed is going down !
Version 0.2
The big idea of version 0.2 was to use one index file and one block file instead of using directories.
The SHA1 hash performs very well to balance hash using the first bits of the 160bits of the full hash inside the index file. I have very few collisions and they can be handled inside the same index block almost all the time requiring rarely more than on extra read per block.
What I forgot was the different in disk speed between sequential and random access. New hard disk can handle more than 100Mo/s throughput but can only access a 8m/s individual block. For block of 4K, this is only 120*4Ko/s equal less than 500Ko/s this is 200 time slower than sequential access !
500Ko/s ! Can you imagine my surprise ? I first thought about slowness in file system cache and used block devices instead. But without any increasing performance ! This is where I made the calculation above and understood the only solution was to use blocks of more than 4K. 64K blocks increase the speed of 16x ! And more, because now index file is more than 16x smaller an can be stay in the file cache all the time.
Version 0.3
Then I needed to handle blocks of more than 4K and rewrote all the code to handle all parameters from a .cfg file.
The index file
 DDUMFS use an index file but no database. The data stored are already well formatted and balanced and don't need any database software like the well known Berkeley DB. The key is the 160 bits SHA-1 hash itself and the value is the 3 or 4 bytes address of the block in the block file. A null address means the node is empty, this is why the value is in front of the node. The use of the SHA-1 insure a good balancing of the hash values and collisions are handled by allocating spare node at regular interval in the hash table using an overflow factor.
DDUMFS use an index file but no database. The data stored are already well formatted and balanced and don't need any database software like the well known Berkeley DB. The key is the 160 bits SHA-1 hash itself and the value is the 3 or 4 bytes address of the block in the block file. A null address means the node is empty, this is why the value is in front of the node. The use of the SHA-1 insure a good balancing of the hash values and collisions are handled by allocating spare node at regular interval in the hash table using an overflow factor.
 The overflow factor impact the number of collisions. Here are the number of collision to fill in the index file with 65536 values. A 1.1 factor means there was 1.1*65536 available positions and then 6553 are left free. Collision handling have very low cost regarding IO and hash calculation. The system has to find a free node after the insertion position of the new entry and move in-between nodes one position right. The slip is almost done inside the same node block and rarely requires to overflow on the next node. The search and the slip are done in memory and the insertion of a new block require only 2 ios to load and re-write the node block. A high factor will lower the collisions but increase the index size. If you expect the index to stay in cache all the time then you will prefer a low factor like 1.2 or 1.3. A factor above 1.6 look to become useless. You can also consider your storage will never be full and free space means also free nodes in index file and low collision rate.
The overflow factor impact the number of collisions. Here are the number of collision to fill in the index file with 65536 values. A 1.1 factor means there was 1.1*65536 available positions and then 6553 are left free. Collision handling have very low cost regarding IO and hash calculation. The system has to find a free node after the insertion position of the new entry and move in-between nodes one position right. The slip is almost done inside the same node block and rarely requires to overflow on the next node. The search and the slip are done in memory and the insertion of a new block require only 2 ios to load and re-write the node block. A high factor will lower the collisions but increase the index size. If you expect the index to stay in cache all the time then you will prefer a low factor like 1.2 or 1.3. A factor above 1.6 look to become useless. You can also consider your storage will never be full and free space means also free nodes in index file and low collision rate.
This is the C version of the magic function that allocate a position in the index file using the first bits of the hash
static void hash2idx(const unsigned char *hash, long long int *node_block, int *node_offset)
{
// calculate the expected address of the hash, extract first c_addr_bits bits
long long int idx=0;
int bits=c_addr_bits;
while (bits>=8)
{
idx=idx*256+*hash++;
bits-=8;
}
if (bits>0) idx=(idx>(8-bits));
// provision to handle overflow
idx=(idx*c_node_overflow)/256;
// address 0 is reserved for unused node
idx++;
*node_block=idx/c_node_per_block;
*node_offset=(idx%c_node_per_block)*c_node_size+c_node_header_size;
}
| Operation on file of 700Mo | Local HD ext4 | ddumbfs C-FUSE | offline Python tools |
|---|---|---|---|
| first copy (write) | 63.4Mo/s | 7.1Mo/s | 8.6Mo/s |
| second copy (write) | 49.8Mo/s | 22.5Mo/s | 17.9Mo/s |
| md5sum (read) | 63.4Mo/s | 69.7Mo/s | 58.1Mo |
| first copy (write) 128k | 63.4Mo/s | 10.3Mo/s | 14.5Mo/s |
| second copy (write) 128k | 63.4Mo/s | 23.5Mo/s | 25.5Mo/s |
DE-Duplication alternatives
Linux alternatives exist, but all try to bring performance or extra features at cost of higher hardware requirements.
Free Front-end for popular Windows and Linux Backup tools.
Monthly archive
- January 2011 (4)
- February 2011 (10)
- March 2011 (6)
- April 2011 (1)
- May 2011 (1)
- July 2011 (4)
- August 2011 (6)
- September 2011 (5)
- April 2013 (1)